
插值法(內插與外插)
發表: 2012 年 02 月 17 日 Filed under: 基本數理 發表留言http://163.13.111.54/numerical_methods/nm_units/interpolation_n_extrapolation_intro_n_polynomial.htm
數學問題探討
當我們在表現資料時,常常會有需要比實際量測點上的值更細密的情況,或者是有需要在範圍外預測其值。
比方說天氣圖的繪製,不論是氣壓或是雨量,都不可能做到處處都有測量站,又例如我們關心一天之中溫度隨時間的變化,但是實際上記錄氣溫的動作可能只是每小時一次,則我們要作一個連續的圖時,就會用到插值法。
插值法的中心議題是:在我們己具備一組表列數(tabulated value)的情況下, 如何得出沒被定到之區域的值。
什麼樣的函數才能被插值,這是數學上討論的間問題,參見課文 p.99 第四段。然而,我們會要用到插值法的場合往往都不知道描述對象背後的函數是什麼形式(但相信其有連續的本質),因此我們也只能盡力求真實。
使用插值法所建立的函數,在表列點上一定要重現原本給定的表列值,否則就不是插值法而是函數近似或曲線擬合的間問題了,它們是不一樣的。
插值的作法,很直觀地來講,就是,(1) 先從表列值來獲得函數 f(x),再 (2) 用函數 f(x) 求出我們所要的任何特定 x 之 f(x) 函數值。然而,比較精密且系統化的數值方法卻不是用這兩個步驟來進行插值,原因是前述兩階段方法對於插值的精密度並沒有控制,效率較差,也比較會有進位誤差。一般在做插值法,是從欲插值點 x 附近的幾個表列點 xi 開始,建立插值函數 f(x),並且也試著網羅更多表列點來插值,看隨著項數變多誤差會不會變小,如此找出最適合的函數 f(x)。
我們會比較希望演算法在從表列值建立插值用函數時,也能提供誤差分析以供我們或程式來判斷。畢竟可用的插值函數 f(x) 並非唯一,而即便是己設定了採用一種方法,如多項式法,也會有該使用多少項才最恰當的問題。
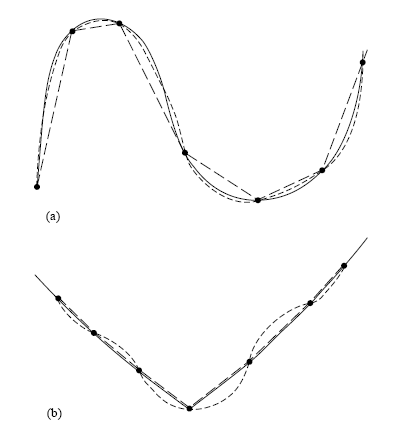
建立插值函數所需之鄰近表列值個數,我們稱之為插值法的 order(階),較高階未必保證得到較合理的插值,這點在多項式插值法尤其如此,要小心注意。詳見課文中之例圖
上兩圖實線都是原現象背後的真正值,短虛線代表低階多項式插值結果,長虛線代表高階多項式插值結果。明顯可見,case (a) 高階者較準確,而 case (b) 則是低階較準確。
線性插值法(Linear Interpolation)
所有的插值法裏面最簡單的莫過於線性插值法,任兩個相鄰的表列點之間必可以拉一條直線把它們連起來,如此在之間的 x 值就都有線性函數 y(x) 可以對應到,利用直線上的斜率必為固定值的特性,其公式是(以 (x1,y1)、(x2,y2) 為兩個相鄰的表列點為例):
(y – y1) / (x – x1) = (y2 – y1) / (x2 -x1)
經整理後得
y = [ (y2 -y1) / (x2 – x1) ] (x – x1) + y1
注意等號的右邊全是 x 與常數,我們因此有了 y(x) 的明確公式可用。
我要求大家對於線性插值法這種較簡單的插值法,應該要能在不看參考資料的情況下做出,即自行把式子寫下來,並且把程式寫出來。
多項式插值法
大家都知道兩點唯一決定一條直線(不轉彎)、三點唯一決定一條二次曲線(會轉一次彎)、四點唯一決定一條三次曲線(會轉兩次彎,有反曲點),等等。這些曲線都是以多項式的形式(變數出現時,些是整數次方)。
一個 n – 1 次曲線的多項式雖有像 y = a(n-1)x(n-1) + a(n-2)x(n-2) + …. + a1x +a0 這樣的通式可以表示出,但必須代入 n 個表列值才能定出 an-1 至 a0 那 n 個係數,一下子不易看出。
數學上有一個 Lagrange 多項式公式,它可以由 n 對 (x,y) 值唯一決定 n-1 階多項式,且公式非常好記, 如課文中的式 (3.1.1)
記法參考:寫下每一項都有係數 yi,分母全是 (xi – xj),其中 i ≠ j,分子則全部都是 (x – xj),一樣是 i ≠ j ,這樣的項共有 N 個相加。我們的式子最高項次一定是 xN-1,符合 (x – xj) 連乘,並且當 x 恰為某一個 tabulated point xi 時,yi 會因分子分母一模一樣抵消成 1 而留下來,而其他具 yj 的項則因其分子必定有 (x – xi) 而成為零,因此 y = yi,符合表列值的定義。
有了上面 Lagrange polynomial 的定義,拿來寫個程式,對任給的 x 求插值,也並非不可以,只是這樣就少了誤差分析及精密度控制的動作。
真正有用的演算法,是 Neville’s 演算法。它定出 Pi 為原本表列值 yi,而 Pi(i+1) 則代表一般表列點是 xi 與 xi+1 所構成的一階 Lagrange 多項式。
Neville’s algorithm 厲害的地方,是發現由低階多項式,可以經由組合而系統化地得出更高階多項式(例如自 P12 及 P23 得出 P123),根據下列關係式:
另外,不同級數間的大小差異,也方便地定義了C 與 D 如何從 P 得到:
進一步推導,C 與 D 更可以從前一級的 C 與 D 得到
如此,我們再回去看上面那個橫向金字塔,比方說想要得 x 的 P1234,可由 低級數的 P 出發,透過 C 或 D 的求得並附加到 P 上,來獲得較高級數的 P(即在 橫向金字塔 中由左而右)越做越精密, 並且可一路上追蹤不同階數多項式之間的誤差度。
課本提供的副程式是 polint,注意你固然可以有多少個表列點就多少個全用(較危險),你也可以只選其中 m 個(比方說 4 )來用,只選其中 4 個的呼叫副程式方法,以 tabulated values 是 18 組 xx 與 yy 為例,要用到點 15 ~ 18 的作法是:
call polint( xx(15), yy(15), 4, x, y, dy )
而有別於全部 18 組都使用的
call polint( xx, yy, 18, x, y, dy )
提醒大家,在 Fortran 的語法裏, call polint( xx, yy, 18, x, y, dy ) 就是 call polint( xx(1), yy(1), 18, x, y, dy ) 的意思,即呼叫副程式所傳的引數是陣列或變數的起始位置。




如何搜尋有序的表
我們前面已經建立了從兩個點唯一決定一條直線的線性插值法, 那麼在已知一系列表列點的情況下,被要求要插值某 x 點上求 y,自然我們必需取用 xi < x < xi+1 的那兩個點 ( xi , yi ) 及 ( xi+1 , yi+1 ) 來做線性插值。簡單的說,現在的問題是,給定 x,如何找到 i ?
我們可以想像,若把程式寫成從最小或從最大的表列點開始與 x 比對,萬一 x 值離那端很遠就會沒有效率 。課本提供了二分法 (bisection) 的方法,首先先判斷 x 有沒有小於 x1 或 大於 xN,若確定 x 在其中則拿其中間點 xN/2 (若 N 非偶數就用 N+1)或來與 x 比,判斷出 x 是在 x1 與 xN/2 之間或是 xN/2 與 xN 之間,然後重覆策略,每次都是取用新上下限的中間點去搜尋 。課本提供 locate 副程式給讀者作二分法搜尋,詳見之。 以下圖例:
如果我們要做一系列相鄰插值點的插值,比方說要做圖產生圖點用,則每個新點會鄰近於舊點。若每次都由最大範圍的上下限開始用二分法,則會花很多冤枉工。有效的策略應是,每次找表列點時,從上一次獲得的表列點開始,如此有最大的機會命中,若小於 x,則以次兩倍步幅變大跳躍向右尋找,直到找到的點比 x 大,再改用 bisection,這樣較有效率。 課本提供 hunt 副程式做上述工作,詳見之。 以下圖例:
最後,還有一個問題:雖然用 locate 或 hunt 可以由 x 得 j,其中 j 與 j+1 表列點會把 x 包夾住,但像是多項式插值法,若我們一次要用(一共是 N 個點中的)m 個點(m 比方說是 4),能使用 j-1、j、j+1、j+2 當然很好,但若 j 太靠近兩側,例如 j 是 1 或 j+1 是 N 的話,j 就不能選作是那 m 個點的中間點了,這樣要如何處理? 答案:使用下列指令,針對 j、m、N 去作運算,則會把邊邊調到剛剛好,為什麼?可自己想一想。
k = min( max(j-(m-1)/2,1) , N+1-m )
呼叫副程式時,像這樣
call polint( xx(k), yy(k), m, x, y, dy )


[C語言數值分析] matrix 矩陣運算 – 問題簡述 / library
發表: 2012 年 02 月 17 日 Filed under: 基本數理 發表留言http://edisonx.pixnet.net/blog/post/83614783
開始前…
在自己下手刻 matrix library 前,請細思:
要自己刻的原因是什麼?因工作需求?因作業需求?還是純粹興趣?
思考完後,或許不需要再看此系列文,反之要做的事情可能是,
去評估一套適合解決手邊問題之 library。
不易解之問題
矩陣問題在線性代數裡佔了不少篇幅,也有不少問題以矩陣模式解之較為合適。
然而在計算機領域,實際解決矩陣問題時,有不少實際狀況必須考量,
較為有名的幾個問題,其中在 CS 領域裡筆者認為「不算好解」的會在後面打 *
另在 (7), (8) 是實作面較為麻煩之事。
(1) 乘法效率 *
如何低於 O(n^3)
(2) 乘法效率 *
一串 matrix 相乘 (如 ABCD) ,相乘次序為何 (如 AB(CD) , A(BC)D ),才能使得在結果正確情況下,乘法次數最少、效率最高?
(3) ill-condition 問題
消除 ill-condition ,這算是較簡單解決之問題。
(4) 消去法效率
消去法種類必須如何低於 O(n^3)
(5) 大型矩陣問題 *
一些較大問題變數個數不小,若在記憶體容量不足之情況下,是否有辦法將大型矩陣切成數個小型矩陣再進行求解動作。
(6) 稀疏矩陣問題 *
稀疏矩陣在資料結構之表示法並不難,難的是如何使其執行效率高。
(7) 如何包成 friendly use class ?
實際包成 class 後發現主要幾個問題點:該用 shallow copy / deep copy、繼承架構該如何設計 、包成 class 後實作上會有不少 side effect 影響效率 (特別是隱喻之 Constructor 便會耗去不少時間) 等,在考量 friendly、effective、multi-thread 情況下,這問題會愈變愈複雜。
(8) 例外處理
目前絕大多數之數值分析在探討時任何 matrix 問題確實會做些基本之例外處理,但一些問題之例外處理並不容易完全處理掉。
Free library
然而實際上也有不少免費 matrix library 已提供,如
1. Matrix Template Library 4 (MLT4) * (不少人用過覺得不錯)
2. C++ Matrix Template Class Library
3. Matrix Expression Templates (MET)
4. Sparse Lib++ * (少數專門處理稀疏矩陣)
5. CAM Matrix / Vector / Array Classes
6. Netmat
7. High Mat C++
(聲明,筆者沒用過任何 matrix library,據說 MLT4 還不錯)
其他有些 Graphic Library ( OpenGL 還是 OpenCV ) 可能也有提供,
也可能有些 library 效能更佳沒紀錄到,也可能有些是 non-Free,
此處便不一一列舉。
convert webpage to an image? RSS
發表: 2012 年 02 月 16 日 Filed under: 網路技術 發表留言http://forums.asp.net/p/1244725/2286975.aspx
JavaScript Image Preloader
發表: 2012 年 02 月 12 日 Filed under: 演算法 發表留言http://www.webreference.com/programming/javascript/gr/column3/index.html
JavaImagePrloader
One of JavaScript’s greatest strengths is the generation of HTML code on the fly, enabling all kinds of effects not possible with HTML alone. One of the hurdles to overcome when generating HTML is to ensure that any images referenced using <IMG> tags are properly loaded. This has been known to cause problems in some circumstances, especially when many <IMG> tags are added at once (even when many of them are referencing the same image). If not done properly (depending on the browser), the images might not be the correct size or load properly or even load at all.
There are a number of mechanisms used to generate HTML with JavaScript:
|
Images referenced using the first method will generally load without any difficulty as the browsers are designed to optimize the downloading of images during the document load/parse phase. All <IMG> tags that reference the same image will be grouped together so that the image is only downloaded once.
This is not true however for the other methods. While most images will load, some browsers (notably Internet Explorer) will render the images incorrectly or sometimes not at all. When <IMG> tags reference the same image they are not optimized, instead the image is downloaded for each <IMG> tag separately. This behavior gets worse as the bandwidth gets narrower. For some reason (unknown to the author), image caching doesn’t seem to affect this.
So why would anyone want to use these methods at all? There are many potential reasons:
1. Maintenance on JavaScript that has already been written this way.
2. HTML that must be added dynamically after the completion of the document load.
When preloading an image, a common mistake is to simply create an Image object and assign its “src” attribute without waiting for the image to load:
var myImage = new Image;
myImage.src = “images/myImage.png”;
This works if the image loads quickly enough. However if the image is used before it has loaded, this preload step will have no effect at all.
To make preloading work properly, the code must wait for the image to complete loading before it is used. In this article, I’ve created an ImagePreloader class that will preload an array of images and call a call-back function when all the images have been loaded into the browser.
The constructor for the ImagePreloader takes an array of image URLs and a call-back function as arguments.
function ImagePreloader(images, call-back)
{
  // store the call-back
  this.call-back = call-back;
  // initialize internal state.
  this.nLoaded = 0;
  this.nProcessed = 0;
  this.aImages = new Array;
  // record the number of images.
  this.nImages = images.length;
  // for each image, call preload()
  for ( var i = 0; i < images.length; i++ )
     this.preload(images[i]);
}
The call-back function is stored for later use, then each image URL is passed into the preload() method.
ImagePreloader.prototype.preload = function(image)
{
  // create new Image object and add to array
  var oImage = new Image;
  this.aImages.push(oImage);
 Â
  // set up event handlers for the Image object
  oImage.onload = ImagePreloader.prototype.onload;
  oImage.onerror = ImagePreloader.prototype.onerror;
  oImage.onabort = ImagePreloader.prototype.onabort;
 Â
  // assign pointer back to this.
  oImage.oImagePreloader = this;
  oImage.bLoaded = false;
 Â
  // assign the .src property of the Image object
  oImage.src = image;
}
The preload function creates an Image object and assigns functions for the three Image events; onload, onerror and onabort. The onload event is raised when the image has been loaded into memory, the onerror event is raised when an error occurs while loading the image and the onabort event is raised if the user cancels the load by clicking the Stop button on the browser.
A pointer to the ImagePreloader object is stored in each Image object to facilitate the call-back mechanism. An optional boolean flag can be added here to indicate whether the image loads properly or not.
Finally, the “src” attribute is assigned to start the loading of the image.
ImagePreloader.prototype.onComplete = function()
{
  this.nProcessed++;
  if ( this.nProcessed == this.nImages )
  {
     this.call-back(this.aImages, this.nLoaded);
  }
}
ImagePreloader.prototype.onload = function()
{
  this.bLoaded = true;
  this.oImagePreloader.nLoaded++;
  this.oImagePreloader.onComplete();
}
ImagePreloader.prototype.onerror = function()
{
  this.bError = true;
  this.oImagePreloader.onComplete();
}
ImagePreloader.prototype.onabort = function()
{
  this.bAbort = true;
  this.oImagePreloader.onComplete();
}
遞迴函數
發表: 2012 年 02 月 12 日 Filed under: 演算法 發表留言http://140.127.40.1/~jwu/c/cpg.htm
http://140.127.40.1/~jwu/c/cpgch6.htm
參數式的意義
發表: 2012 年 02 月 12 日 Filed under: 基本數理 發表留言參數式是由"一個點"加上一個"方向向量"所組成,即形成直線的參數式
參數式就是表示直線,無論在空間或在平面
參數式是表示那個方向上的所有的點,點即構成直線
用參數式表示點,即那條線上所有可能的位置
ex:(1+t,2+t,3+t) 是假設那條線上的某一點
C & WIN32 WINDOWS SYSTEM (OS) PROGRAMMING: README FIRST
發表: 2012 年 02 月 07 日 Filed under: 計算機相關 發表留言http://www.tenouk.com/cnwin32tutorials.html
Win32 programming tutorial is implementation specific to Windows operating system, that is for 32 bit Windows operating system family. Now we already have the 64 bit Windows Operating System such as, Windows XP Professional x64 Edition. However the fundamentals in system programming not much change, the general principle and concept still retained. Based on the MSDN documentation but re-arranged in a readable and understandable sequence, avoiding a lot of cross references, this tutorial tries to investigate the Windows 2000 (NT5) family system through Win32 C programming.
Why does my text look different in GDI+ and in GDI?
發表: 2012 年 02 月 06 日 Filed under: 視窗圖形影像 發表留言http://windowsclient.net/articles/gdiptext.aspx
GDI+ Text, Resolution Independence, and Rendering Methods.
Or – Why does my text look different in GDI+ and in GDI?
- Summary
- Resolution independent layout
- Grid fitting and hinting, and their disproportionate effect on glyph widths
- How GDI+ compensates for Grid Fitting.
- How to display adjacent text
Summary
GDI+ text layout is resolution independent, and thus different from GDI.
Forms built with GDI+ text look the same at all resolutions and when printed.
In grid-fitted rendering (the default), font hinting usually changes the width of glyphs. When a sequence of glyphs all increase significantly in width GDI+ may have to close up the text to remain resolution independent. In pathological cases (such as a long run of bold lower case ‘l’s in 8 pt Microsoft Sans Serif on a 96 dpi display), the space between some letters can disappear completely.
Resolution independent layout
The GDI+ APIs DrawString and MeasureString lay out text independent of device resolution, thus a paragraph of text takes the same number of lines, no matter what device it is displayed on. There are many benefits:
- If a form field is sized to fit some static text on one developers machine, it will fit that text on all machines the application runs on, regardless of screen resolution, or accessibility settings.
- When the form is printed, it will layout the same as it looks on the screen.
- A form recorded in a metafile retains its layout.
Consider the forms designer working with resolution dependant layout. A box is defined on the form for some text – a title maybe. The title is typed, and the box adjusted to fit. Sadly, unlike the lines, the text will not scale linearly with resolution, so the box will only fit correctly at the resolution the designer was working in.
For graphical objects, such as lines and pictures, a different device resolution simply means a different scale factor at display time. A line 100 pixels long on a 96 dot per inch (dpi) display, will be drawn 125 pixels long on a 120 dpi display, and 625 pixels long on a 600 dpi printer.
For text, the font height will be scaled appropriately for the device resolution: a font that is 20 pixels high on a 96 dpi screen will be rendered 25 pixels high on a 125 dpi screen and 125 pixels high on a 600dpi printer. However the width of individual glyphs will scale only approximately with the height. The exact width is also dependant on hinting (or grid fitting) that has been included in the font to adjust glyphs for legibility.
Grid fitting and hinting, and their disproportionate effect on glyph widths
Grid Fitting, also known as hinting, is the process of adjusting the position of pixels in a rendered glyph to make the glyph easily legible at smaller sizes. Techniques include aligning glyph stems on whole pixels and ensuring similar features of a glyph are affected equally. Font designers spend many hours per glyph defining hinting.
For example, consider the letters ‘elsw’ from Times New Roman, rendered at 8 points on various resolutions, using GDIs standard grid fitting.

In this chart, each glyph is drawn at high resolution in gray, then the actual pixels representing it at a given size and dpi are drawn on top as black circles. 96 dpi is the most widely used display resolution, also known as ‘small fonts’ in control panel/display/settings/advanced/general. 120 dpi corresponds to ‘large fonts’. 150dpi is becoming a common laptop LCD screen resolution. 600dpi is a current low end laser printers resolution.
Notice how at 96 dpi (standard screen resolution) there are very few pixels in an 8pt glyph. The 8pt 96dpi lower-case ‘s’ for example has almost none of the character of the glyph it is intended to portray.
The figures below each glyph show the difference between the designed width of the glyph, and the width after grid fitting. The left hand figure is the difference as a positive or negative percent. The right hand figure is the difference in pixels at the display resolution. For example, the top left glyph, the 8pt 96dpi lower-case ‘e’ is about 11% or .61 pixels narrower after grid fitting.
If there were no grid fitting, we would expect the only difference between designed and displayed width would be the effect of rounding to the nearest pixel. In this case we would never see a width difference of more than 1/2 a pixel. At the highest resolution (2400dpi) this is indeed the case, the biggest difference seen here amounting to 0.37 pixels.
However at lower resolutions the effect of grid fitting can exceed or swamp simple rounding.
How GDI+ compensates for Grid Fitting.
When grid fitting generates glyphs narrower than designed
The worst case above is the 96dpi lower-case ‘w’. ‘w’ is a particularly difficult glyph to hint well: the stems must appear symmetrical, evenly spaced and equally thick. Careful hinting has resulted in a good appearance, but the hinted glyph is over 2 pixels narrower than its design width. A string composed only of 8pt 96dpi ‘w’s will be 23% shorter when grid fitted.
When GDI+ displays a line of grid fitted glyphs that are shorter than their design width, it follows these general rules:
- The line is allowed to contract by up to an em without any change of glyph spacing.
- Remaining contraction is made up by increasing the width of any spaces between words, to a maximum of doubling.
- Remaining contraction is made up by introducing blanks pixels between glyphs.
The following example shows how GDI and GDI+ display the string ‘wwwww wwwww wwwww wwwww wwwww’ in 8pt Times New Roman at 96dpi with grid fitting.
| GDI (resolution dependant) display | |
| GDI+ (resolution independent) display |
This shows
- GDI+ is using design widths to layout the string, and so measures he whole string longer than GDI.
- GDI+ has allowed the string to stop short of the far end by 1 em
- GDI+ has placed remaining expansion in the spaces.
The following example takes the same strings with the spaces removed. Now GDI+ cannot use the spaces to compensate for the contractions caused by grid fitting and instead inserts an extra pixel between some of the glyphs.
| GDI (resolution dependant) display | |
| GDI+ (resolution independent) display |
When grid fitting generates glyphs wider than designed
Now consider the following chart of Microsoft Sans Serif Bold 8pt. Microsoft Sans Serif is the default user interface font for Windows 2000 and higher.

In this case most of the glyphs are wider than design at 96 and 120dpi. Although many are not much larger, there are some particularly difficult cases.
Consider a string of 96dpi lower-case ‘l’s. Although each ‘l’ is only .16 pixels wider than its design width, a run of just 7 ‘l’s is enough to exceed the runs design width by a whole pixel. In this case we need to compress the string by one pixel. Unfortunately the shape of the lower case ‘l’ behaves very poorly when a pair are overlapped by one pixel: since there is only one blank pixel column, overlapping causes the adjacent glyphs to become solid.
The following example shows a run of 19 ‘l’s displayed by GDI and by GDI+
| GDI (resolution dependant) display | |
| GDI+ (resolution independent) display |
Notice how in GDI+ the last two ‘l’s are touching.
You can also see in this example that GDI+ adds a small amount (1/6 em) to each end of every string displayed. This 1/6 em allows for glyphs with overhanging ends (such as italic ‘f‘), and also gives GDI+ a small amount of leeway to help with grid fitting expansion.
How to display adjacent text
Maybe you would like to display two strings side by side such that they appear as one string. You might do this if you are writing an editor, or are displaying text with a formatting change inside the paragraph.
Warning: Building lines of text with multiple DrawString calls is inherently unable to display general International text. In particular, In Arabic, Hebrew, Farsi and other right-to-left languages, strings advance generally from right to left, with localized order reversal around numbers and around western phrases. DrawString handles within one output, using bidirectional behaviour defined by Unicode. The rules are complex. See The Unicode Standard Version 3.0 section 3.12.
The default action of DrawString will work against you in displaying adjacent runs: Firstly the default StringFormat adds an extra 1/6 em at each end of each output; Secondly, when grid fitted widths are less than designed, the string is allowed to contract by up to an em.
To avoid these problems:
- Always pass MeasureString and DrawString a StringFormat based on the typographic StringFormat (GenericTypographic).
- Set the Graphics TextRenderingHint to TextRenderingHintAntiAlias. This rendering method uses anti-aliasing and sub-pixel glyph positioning to avoid the need for grid-fitting, and is thus inherently resolution independent.
The following table compares GDI, GDI+ GridFitted and GDI+ anti-alias text for the examples considered above.
| GDI (resolution dependant) display | |||
| GDI+ (resolution independent) grid fitted display | |||
| GDI+ (resolution independent) anti alias display |
While Anti-alias text can look a little gray at very small sizes (this is 8pt), it shows the shape of the glyphs far more accurately than grid fitted text, and does not suffer from the glyph position adjustment described above for grid fitting.
注重成果,變革才會成功
發表: 2012 年 02 月 05 日 Filed under: 管理評論 - 作者: VinsonHsieh 發表留言请告诉我 代码页(Codepage)和 Unicode 的区别和联系是什么?
發表: 2012 年 02 月 01 日 Filed under: 計算機相關 發表留言http://zhidao.baidu.com/question/261569922.html
我们常说汉字的"内码"与"外码"。
内码是汉字在计算机内部存储,处理和传输用的信息编码。它必须与ASCII码兼容但又不能冲突。
所以把国标码两个字节的最高位置'1',以区别于西文,这就是内码。汉字的输入码称为"外码"。输入码即指我们输入汉字时使用的编码。常见的外码分为数字编码(如区位码),拼音编码和字形编码(如五笔)。
再说区位码,"啊"的区位码是1601,写成16进制是0x10,0x01。这和计算机广泛使用的ASCII编码冲突。为了兼容00-7f的 ASCII编码,我们在区位码的高、低字节上分别加上A0。这样"啊"的编码就成为B0A1。我们将加过两个A0的编码也称为GB2312编码,虽然 GB2312的原文根本没提到这一点。
内码是指操作系统内部的字符编码。早期操作系统的内码是与语言相关的.现在的Windows在内部统一使用Unicode,然后用代码页适应各种语言,"内码"的概念就比较模糊了。我们一般将缺省代码页指定的编码说成是内码。内码这个词汇,并没有什么官方的定义。代码页也只是微软的一种习惯叫法。作为程序员,我们只要知道它们是什么东西,没有必要过多地考证这些名词。
所谓代码页(code page)就是针对一种语言文字的字符编码。例如GBK的code page是CP936,BIG5的code page是CP950,GB2312的code page是CP20936。
Windows中有缺省代码页的概念,即缺省用什么编码来解释字符。例如Windows的记事本打开了一个文本文件,里面的内容是字节流:BA、BA、 D7、D6。Windows应该去怎么解释它呢?是按照Unicode编码解释、还是按照GBK解释、还是按照BIG5解释,还是按照ISO8859-1 去解释?如果按GBK去解释,就会得到"汉字"两个字。按照其它编码解释,可能找不到对应的字符,也可能找到错误的字符。所谓"错误"是指与文本作者的本意不符,这时就产生了乱码。
答案是Windows按照当前的缺省代码页去解释文本文件里的字节流。缺省代码页可以通过控制面板的区域选项设置。记事本的另存为中有一项ANSI,其实就是按照缺省代码页的编码方法保存。
Windows的内码是Unicode,它在技术上可以同时支持多个代码页。只要文件能说明自己使用什么编码,用户又安装了对应的代码页,Windows就能正确显示,例如在HTML文件中就可以指定charset。
有的HTML文件作者,特别是英文作者,认为世界上所有人都使用英文,在文件中不指定charset。如果他使用了0x80-0xff之间的字符,中文Windows又按照缺省的GBK去解释,就会出现乱码。这时只要在这个html文件中加上指定charset的语句,例如:
<meta http-equiv="Content-Type" content="text/html; charset=ISO8859-1">
如果原作者使用的代码页和ISO8859-1兼容,就不会出现乱码了。????????????????????????
进一步的参考资料
"Short overview of ISO-IEC 10646 and Unicode" ()
